

父の先見



父の先見
解析が生む新しい価値
角川学芸出版 2015
装幀:芦澤泰偉・五十嵐徹
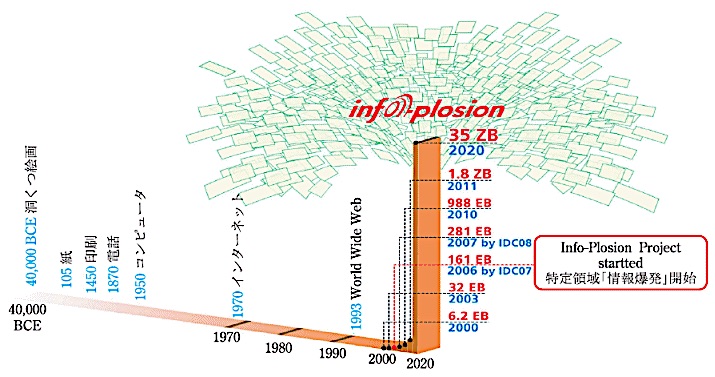
米国IDCの推計によると、2013年の1年間でインターネットに蓄積されたデータは約2ゼタバイト(=2000エクサバイト=2000×1000×1000テラバイト)だった。この数字は20世紀終わりまでに人類が蓄積したデータ量の300倍以上になるらしい。
どういう計算をしたのか知らないが、このままいくと2020年までにはこれが2年ごとに2倍ずつ増える。「増える」ということは「溜まる」(ゴミも)ということで、このべらぼうな情報怪物の総体が、いまビッグデータと呼ばれているものの正体だということになる。
コンピュータに入れた情報だけならここまで急激に膨れ上がりはしなかった。実世界の状況や動向がデータとしてセンシングされて、次から次にセンサーを通してネットに入ってくるから、こうなった。
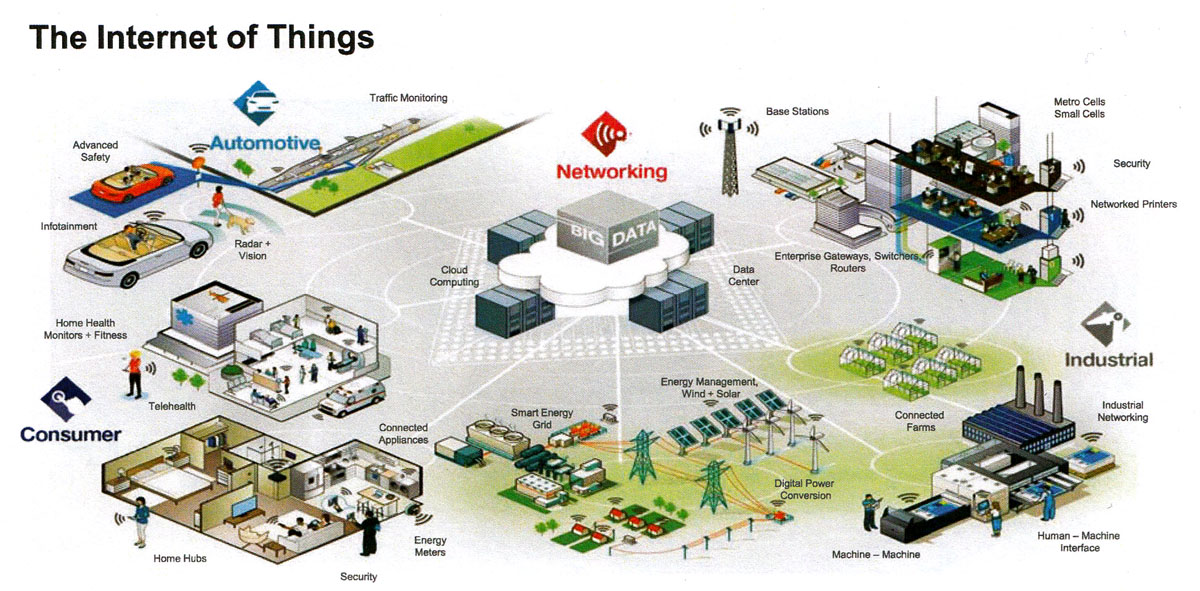
仮に一人が1日10件の検索をするとして、3000万人の1週間の検索ワードの総計はざっと21億アイテムになる。また1人のネットショッピングのクリックデータが1日10件だとすると、1000万人の1年間のクリックデータは360億アイテムになる。いまは車からも1秒ごとに現在位置やアクセル・ブレーキを踏むたびのデータが出ているから、数千万台の車がいっせいに送り出しているデータも1日で数十兆件を超える。加えて今後はモノが情報を発する。IoT(Internet of Things)によって2020年には約500億のモノがインターネットに結合されると予想されるので、ネットは実世界のモノが送り出す動向データによっても気違いじみて溢れることになる。
こういう狂ったような情報過剰堆積状態を、いつしかまとめて「ビッグデータ」とか「ビッグデータ時代」と言うようになった。こんな無責任な用語でいいのかと思うほどいいかげんなネーミングだ。素直に「めちゃんこ大量データの交錯時代」と言ったほうがいいだろう。
だが、この現象はもはやゼッタイに止まらないものになっている。となると、これはいったい何がおこったのか。たんなる情報洪水や情報爆発ではない。どう見ても高度結合が行き過ぎて「過剰結合状態」になり、世界は「思考感染状態」になったということなのである。
昨年、「角川インターネット講座」全15巻が出揃った。こういうインターネット情報技術文化をめぐる一般向けのシリーズ本は日本では初めてで、それを横文字KADOKAWAになって川上量生君のドワンゴとの一蓮托生を選んだ版元が出版したというのも象徴的だった。
出来はまちまちだったが、構成はそれなりに第1巻の村井純『インターネットの基礎』から始まって、まつもとゆきひろ編『ネットを支えるオープンソース』、川上量生編『ネットが生んだ文化』、近藤淳也編『ネットコミュニティの設計と力』、西垣通編『ユーザーがつくる知のかたち』、高野明彦編『検索の新地平』、東浩紀編『開かれる国家』等々がほどよく並んで、最終巻の伊藤穣一編『ネットで進化する人類』まで、うまく取り揃えていた。
今夜採り上げた本書は、そのうちの第7巻にあたる。情報通信研究機構理事長の坂内正夫の監修のもと、情報学研究所の分散システムのプロ佐藤一郎、慶応の統計学者の古谷知之、日立でウェアラブルセンサーを開発してきた矢野和男、東大生産技研でITSセンターを仕切っていた桑原雅夫、ホンダでインターナビを発案したアマネクの今井武、NTTの機械学習研究の上田修功、システムコンサルタントの松本直人、ICT関連に強い弁護士の森亮二らが執筆した。
シリーズのすべての巻がおもしろいわけではなく(期待はずれも多い)、この巻の各章がそれぞれ充実していたというわけでもないのだが、とはいえ一度は、ビクター・マイヤー=ショーンベルガーの『ビッグデータの正体』(講談社)、高橋範光の『道具としてのビッグデータ』(日本実業出版社)、ビル・フランクスの『最強のビッグデータ戦略』(日経BP社)、トーマス・ダベンポートの『データ・アナリティクス3.0』(日経BP社)、城田真琴の『ビッグデータの衝撃』(東洋経済新報社)などといったビジネス型の紹介書ではないビッグデータ本を採り上げておこうと思って、比較的バランスのよい本書を選んだ。

宇宙や生命における情報はエントロピーの逆数であらわせる。熱力学的な秩序が「でたらめさ」に向かっていくにつれエントロピーが増大していくと、そのぶん情報が薄くなる(物理量的には減っていく)。シャノンが確立した通信工学においても、情報通信は通信回路でのノイズを洗い落とすことで成立する。これがエンコードとデコードのあいだでなされていることだ。
ところが情報社会や情報経済や情報文化にあっては、情報はスリムな秩序化をめざすとはかぎらない。どんな情報も内臓脂肪で肥満しているし、たいていいっぱいのノイズを引き連れていて、もともとがリダンダンシーっぽくてゴミ含みなのである。こんなことは人間の文明が言葉を交わしあい、それらを文字や絵画に記録するようになってからずっと続いていたことで、驚くにはあたらない。
そもそも「言語」や「意味」がそう出来ているのだから、情報は溜まりすぎると使い勝手がわからなくなるほどぐちゃぐちゃになるわけだ。さまざまな「情報含み資産」が見当もつかないほど入り混じるのだ。言い換えれば、どんなコミュニケーションも記録上では必ず情報エントロピーが上がるのだ。
この現象をインターネットとセンシング・データの出し入れがいやというほど一挙に加速していったわけである。これがいまおこっている過結合状態だ。誤解のないように言っておくが、インターネットそれ自体が過結合の正体なのではない。そこにセンサーネットワークがくっついているから、情報が爆発的に増えた。
ちなみにセンサーネットワークとしては、現状では3G、4G、LTE(Long Term Evolution)などのモバイル回線、Wi-Fiなどが使われている。そのうち、次世代電力量計スマートメーターの情報収集に採用されるWi-SUN(Wireless Smart Utility Network)やIoTなどが活用されるだろう。
問題はそうやってがんがん溜まっていくビッグデータを、さあ、いったいどのように処理していくかということだ。
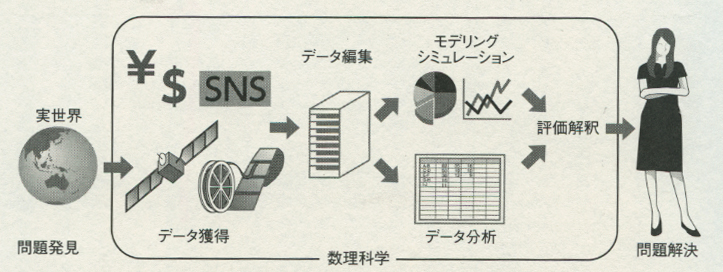
処理にあたっては、いまのところは次のような手順でやっている。①前処理としてデータの単位や目盛を整える。インチ、センチ、ドル、円、平米、坪などがバラバラでは困るからだ。②誤差や混入ノイズも丹念に取ってデータクレンジングをしておく。そのうえで、③クラウド化に先行してデータクラウドをつくるデータセンターを動かしていく。これは19インチラックをずらりと並べて対応する。
ついで、④ビッグデータを複数のサーバーに分割処理するハドゥープ(Hadoop)などを動かしていく。これはグーグルがウェブの収集データを検索エンジンにかけるために開発したマップリデュースの処理技術を応用したもので、最近はアパッチプロジェクトに取り込まれている。
そうした仕分けを施したデータは、これだけではたいした「警告」や「意味」ももたらさない。そこで、⑤統計分析、データマイニング、多変量解析、機械学習などの試みを導入していく、というふうになっていく。データマイニングは大量のデータを分析してこれまで知られていなかった情報を取り出すこと、すなわち情報採鉱のことである。多変量解析は多くの変数からなるデータを統計的に扱って現象の原因を見つけたり、今後の予想のためのデータのグルーピングをすることをいう。
ざっとはこういうことをするのだが、しかし、この程度の①から⑤までのようなやりかたでは、イマイチ、いやイマサンなのである。ビッグデータを生かした(活かした、活用した、活性化させた)とは言いがたい。これで「成果」を取り出せたとはかぎらない。
総じて、現在のビッグデータ解析は「意味」を扱いきれず、結果、「意図」を掴み切れないものにとどまっている。これではいつまでたってもマーケティングデータの高速処理に終始して、新たな「価値」の発見にはつながらない。ビッグデータを話題にするときは、つねにここが問題なのである。
編集工学をしていると、のべつ情報と知識と社会動向の巨壁や荒波や雑草に付き合うことになる。それゆえ編集工学の基本的な役割は「情報化」されている情報、ないしは情報化があやしい情報動向に、新たな「編集化」を次々にほどこして、そこに何種類もの翼を付けていくことにある。
そのためには情報と知識の動向に対して、こんなことをする。(a)読み筋の摘出の整理、(b)何段階かの情報グルーピングのアラインメント、(c)仕分けなおし、(d)ラベルやタイトルの付け換え、(e)情報格納庫のアドレスのリロケーション、(f)分母の入れ替えと新たな分子の想定、(g)潜在するメタファーの発見、(h)既存の応用例の列挙と比較、(i)シソーラス構造の想定、(j)情報構成表のリフォーム、(k)メタフレームの適用、(l)物語との関連化、(m)情報編集リストラクチャリング等々‥‥。
これが編集工学がつねに志している作業なのだが、なぜこんなふうにするかというと、これらすべての情報アイテムや知識アイテムたちが含み資産としている「意味」をユニットやパターンやエージェントやエッジなどに分能させながら動きやすくするためだ。編集は「意味」を動かして「価値」を新たに発見する作業なのである。
ところが、である。これらの手立ての多くは、ふつうは「定性的な作業」だと思われているので、定量化ができないか、もしくはしにくいとみなされてきた。
そのため、従来は多くの情報や知識に対してもっぱら統計的な手立てがほどこされ、ひたすら数値によって情報を処理することばかりが重視されてきたのである。数理科学はどこかで「定性」を苦手にしてしまったのだ。
けれどもビッグデータ時代になると、統計処理された定量的データを「意味」のウェイトによって定性的に編集せざるをえなくなってきた。数値データの羅列ばかりでは、ビッグデータからの「声」が聞こえない。これでは困るのだ。企業はつねに「価値」を見いださなければならないからだ。
どうしたら定性的な分析ができるのか。その方法が見えてこないので、とりあえず多くの企業や自治体はビッグデータ解析に大量の人員(データサイエンティスト)と機械学習ソフトと人工知能(アタマが悪いAI)と、けっこうな資金を投入することにした。それがこの10年の作戦だった。けれども、いまもってなお「定性の獲得」には至っていない。
明治初期、福沢諭吉が『文明論之概略』(412夜)で「スタチスチク」というふうに「統計学」(statistics)を紹介し、箕作麟祥がモロー・ド・ジョンネの『統計学』を翻訳してこれを「政経国表」と見立ててから、ほぼ150年近くたった。
その間、ホレリス計算表による国勢調査が進み、コンピューティング・タビュレーティング・レコーディング・カンパニー(のちのIBM)が起業し、1925年にはロナルド・フィッシャーが統計学(いまでは古典統計学という)の一般化の先頭を切った。
1930年代にはベイズ統計学(ベイズ確率)とチューリングマシンが顔を揃えると、そこからはENIACに始まる巨大な電子計算機からメインフレーム・コンピュータによる「ビットとの戦い」まで、ITはどかどかどかどかと発進していった。あとはすべてがダウンサイズされ、メモリー量を上げ、電子回路の精緻化をめざすパソコン時代にひたすらまっしぐら。史上初のパソコン「アルテア」のメモリーは「荒海や佐渡によこたふ天の川」を入力しただけでいっぱいだったのに、2008年のマイクロプロセッサのメインメモリー容量は1ギガバイトなのである。40年間で数百万倍になったのだ。
そこから先は知っての通りで、インターネットがくまなく張りめぐらされ、グーグル検索エンジンによる協調フィルタリングの登場以降はSNSにもスマホにもクラウド・コンピューティングにも、やたらめったら統計確率マッチングの値が進出して、情報社会の隅々まで浸潤していったのである。
こんな驀進が次々に連打したために、さすがに市場や流通のほうもいろいろな作戦変更をせざるをえなくなった。欲望をはかる尺度が変わってきたからだ。こんな作戦変更の一例がある。
1920年代にサミュエル・ローランド・ホールが広告宣伝戦略の決定的なメルクマールとして「AIDMA」(アイドマ)の法則を打ち出した。これはA(Attention:注意を惹く)、I(Interest:興味をもたせる)、D(Desire:欲しがらせる)、M(Memory:忘れられなくする)、A(Action:購入させる)の5発で消費者をぶっとばせということだ。
それが20世紀が終わるころには、マーケッターたちはこっそりAIDMAのイニシャルを入れ替えて「AISAS」(アイサス)と言うようになった。DがS(Search:検索させる)に、MがS(Share:情報を共有させる)に変わったのだ。
あとは一瀉千里、あっというまのデジタル情報大錯走である。ユーザーや消費者は居ながらにして、いやどこに居ようとも、手元のスマホから世界中の情報と知識を引き出せるし、企業のマーケティングと広告戦略はAISASさえあれば何とでもユーザーとの勝負ができると思いこむようになったのだ。

かくして「データで何かを言ってもいい社会」の夜が明けてから150年しかたっていないのに、いまやすっかり「データだけがものを言う社会」になったわけである。ユビキタス社会とは「データで何か」ではなくて「データですべて」なのだ。
そうなったのは情報がことごとくデジタル化され、コンピュータが記録と計算と設計を代行し、サーバーとインターネットが世界中を覆い、それらにコーパスが入力され、POSや数々のセンサーやSNSからネットに送り込まれる情報知識動向が急激に膨大になっていったせいだった。
ところが、またもやところがだ。こうして溜まってしまったビッグデータをどうするかという、いよいよの段になって(つまりクラウド化もSNSもハッキングテクノロジーもすっかり世界に広まってしまった段になって)、急激にかつ信頼できる「とても賢いデータ・アナリシス」が必要になってしまったのである。しかしそんな便利なものがあるはずはない。定量化に走ってきた報いは大きかったのである。
本書は、この急激な焦りともいうべきビッグデータ時代において、どんなおっとり刀が使われているかを報告したものだ。
そもそも統計学は「不確実性」を扱うための手立てであって、20世紀前半の統計業界を席巻したロナルド・フィッシャーの最尤法(さいゆうほう)や線形判別関数だって推測統計学の域を出るものではないし、だったら「パラメーターも不確実性のある確率変数にしてまえ」というベイズ統計学が提唱されて、これがいまもって大流行になっているのだが、これとて金融工学の道具になったり行動経済学の下敷きになったりで、「不確実な社会における集積された情報」とは何かということの解答幇助などにはなっていない。
そもそも、ビッグデータに取り組んで悪戦苦闘している今日の試みは、ふりかえってみれば70年代にリレーショナル・データベースの元祖となった“System R”を開発し、90年代にビッグデータ時代を予測したジェームズ・ニコラス・グレイの「データ集約型科学」(Data-intensive Science)の提案の範疇を、いまだ出ていないままなのだ。
これをいいかえれば、今日のビッグデータ技術は統計解析技術と機械学習技術とデータマイニング技術との“合体”にすぎないということになる。統計的機械学習は「予測」のため、データマイニング技術は「列挙」のためである。
それでもさまざまな進展はある。機械学習には「教師あり学習」(supervised learning)と「教師なし学習」(unsupervised learning)の技術が別々に発達してきたのだが、「教師あり学習」のパターン認識モデル技術ではいっときSVM(Support Vector Machine サポートベクターマシン)が活躍した。「教師あり学習」というのは、見えている入力データが与えられているときに、見えなかった出力データを正しく予想しようというプログラムのことをいう。
SVMは1995年にウラジミール・バプニックが考案した汎用パターン認識の手法である。カーネル関数という高次元写像を使って簡便に線形識別をするもので、特徴ベクトルが次元圧縮できるので大活躍した。
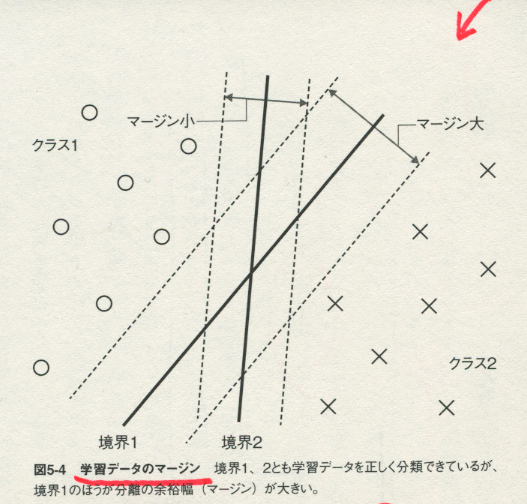
パターン認識の数理化にあたっては、以前から「次元の呪い」がうろついていて、特徴ベクトルの次元が大きくなると学習機械のパラメータがふえて複雑になりすぎる。SVMはそこをクリアしたのだ。
SVMは「マージン最大化基準」を導入したことでも成功した。マージン(余裕度)という概念を入れた。ふつう、線形的な学習プロセスを識別するには、識別誤り率(どれくらい識別を誤るのかという比率)を入れて計算するのだが、SVMはそこを「識別境界付近でどれくらい分離の余裕があるか」というメトリックを入れて新たな学習基準にした。
これはなかなかのアイディアだった。とはいえ、これらはいずれも「教師あり学習」のモデルなのである。
「教師なし学習」のほうは、機械学習において「出力すべきもの」があらかじめ決まっていない学習プロセスのことをいう。入力データだけしかないので、そのためデータの背後にひそむであろう構造的な特徴を抽出する必要がある。
もともとビッグデータには多くの非構造データ(たとえばウェブ上の膨大なテキストデータなど)がふんだんにまじっている。その玉石混淆のデータ状態からなんとか潜在情報の特徴を浮かび上がらせるには、膨大なデータからせめて「単語の共起」(文書や文章の中にある単語と別の単語が同時にあらわれること)などを学習させて、トピックを摘出できるようにしなければならない。似通ったトピックのテキストでは関心事についての言及傾向が共通するだろうから、この性質をいかしたモデルをつくるわけである。
2003年にデイビッド・ブライが提案したLDA(Latent Dirichle Allocation)がそういうモデルとして有効になった。単語知識や文法に頼らずにテキスト群からのみトピックを抽出する学習モデルである。
クラスタリング技術も変化してきた。非構造データを代表する関係データの解析には、かつてはSNS情報のように各人を特徴付けるプロファイルが必要だったのだが、これを「教師なし」の統計手法で「つながり関係」のみのクラスタリングでカバーできるようにした。
購買ログデータの「教師なし」機械学習では、客と商品を同時にグルーピングする手法も開発された。顧客群と商品群のデータから購買ログの中の関連性の強いグループを自動抽出する。顧客と商品のグループが同時にクラスタリングできるので、しばしば非クラスタリングとも言われる。
こうした手法はやがてディープラーニング(深層学習)と呼ばれるようになった。よく知られるのは2012年の画像認識コンテストで優勝したDNN(Deep Neural Network)である。「グーグルの猫」はユーチューブから任意に取り出した1000万枚の画像を通して猫の顔を認識する方法を自ら獲得して、DNNを有名にした。
DNNは従来のパーセプトロン型(ああ懐かしい!)のニューラルネットワーク・モデルを多層にしたもので、2006年、トロント大学のジェフリー・ヒントンが(かつてボルツマン・マシンで名を馳せた)ネットワークの中間層を3層以上にしたものを「ディープラーニング」の基本モデルと定義した。
その後、短期間でDNNはずいぶん普及したが、それで事が足りるわけではない。最大の欠点は、結果にたいする説明ができないということだ。
音声認識や画像認識なら、認識精度がある程度高ければ、その結果が“誰々さん”であるとか、“猫”であるとかの説明をコンピュータに求める必要はない。けれどもこれが企業の経営にかかわることや新商品の開発にかかわることとなると、データ担当の幹部から「DNNによるとこの開発によって来月の利益が11パーセント上がります」という報告を受けたとしても、その理由の説明がほしくなる。DNNのみならずディープラーニングはそこがブラックボックスになっている。因果関係には答えられないのだ。

業界では、いまやビッグデータは石油に代わる資源になりつつあるらしい。ビッグデータは情報の石油なのだ。だったらデータベースは情報油田なのだろう。実際、そこからコンピュータ・ネットワーク製油所が情報パイプラインを通してビッグユーザーや個人の手元に向かって、“なんでも油”をどんどん、ざぶざぶ届けるようになった。
それがビッグデータ時代なのだが、そういう威勢のいい掛け声のわりには新たな展望をもてないままにある。情報精製技術にムラがあるからだ。
そもそもデータベースの機能に限界がある。今日のデータベースは、ほとんどがリレーショナルデータベース(RDB)による“均一な情報製油”ばかりになっていて、それを支える管理システム(RDBMS)だけがわがもの顔で世にはびこった。
RDBの歴史は1970年のIBMのコッドの論文に端を発し、サンノゼ研究所のシステムRプロジェクトをへて、DB2、SQL/DS、オラクル、2004年にカリフォルニア大学バークレーが開発したIngresのオープン化‥‥というふうに発展してきた。世代的には、第1世代が階層型、第2世代がリレーショナルモデル、第3世代がオブジェクト指向モデルという段階を踏んだ。
けれども、こうしたデータベースは、実世界の一部の情報を管理できそうなデータを集まりにして、それをコンピュータに写像したものだ。実世界の写像情報だから、ビジネス界ではもっぱら生産管理・販売管理・在庫管理などに応用されるのだが、そのためにER図などの図法による概念データモデルと、実装可能な状態をつくる論理データモデルと物理データモデルを使い分けざるをえなかった。概念データモデルは現実の実務をモデルにマッピングしたもので、論理データモデルはコンピュータで実装できる範囲に限定されている。
RDBがこうした限定のなかで能力をのばすには、できるだけ概念モデル段階でカテゴリーをふやしておくことがコツなのだが、そのため、ERモデル(Entity Relationship model)は実世界のデータを何がなんでも、エンティティ(entity)、リレーションシップ(relationship)、属性(attribute)の3つで表現してしまうというモデルになった。
簡単に説明しておくと、エンティティは分析対象がどんな範囲を扱っているかをあらわしている。「社員」「部門」「顧客」「商品」「注文」「在庫」などがエンティティ・タイプになる。そのタイプの中にエンティティ・オカレンス(あるいはインスタンス)がぶらさがる。「社員」というタイプの中に、「Aさん」「契約社員」「要注意人物」などがくっつくわけだ。
リレーションシップはエンティティ間の結び付きを表現する。「部門」と「社員」のあいだを「所属する」「勤務する」などで結ぶ。これに結び付きの次数が加わり、さらに同じエンティティが異なる役割として2度以上かかわることを示す再帰リレーションシップが付与される。
属性はエンティティとリレーションシップの性質や特性をあらわしておくもので、「社員」の項目には「氏名」「入社年月日」「生年月日」「住所」「家庭環境」「趣味」などがアトリビュートされる。リレーションシップにも属性をつける必要がある。
しかし、結局はこんなことしかできないのである。RDBは集合論をベースにしたシステムで、問題解決のために設計された。それゆえスキーマの柔軟性よりもクエリーの柔軟性を重視し、行と列からなる2次元のテーブルで実装するようになっている。やりとりには主にSQL(構造化問い合わせ言語)を使ってきた。けれども、データ型は数値型・文字列型・日付型・BLOB型というお決まりの紋切り型ばかりで、おもしろくもなんともない。おもしろくするには既存のテーブルを組み合わせ、結んで開いてをするしかないのだが、それもまた集合論に規制されていく。
むろん、業界は手をこまねいていたわけではない。これらから少しでも離陸するためのデータベースが試みられもした。リレーショナルDB(Postgres)、キーバリューストア(Riak,Redis)、列指向型DB(HBase)、ドキュメント指向型DB(MongoDB,CouchDB)、グラフDB(Neo4j)などが出回ったのだが、これらにも非構造データを含むビッグデータから「意味」と「理由」を読み取ることは簡単ではなかったのである。
業界からすると、ビッグデータが備えてほしいものは、いくつもの「V」である。ボリューム(Volume データの規模)、バラエティ(Variety 情報と知識の多様性)、ベロシティ(Velocity 情報処理速度の速さ)、ベラシティ(Veracity 正確な予測とそのプロセスの提示)、そしてバリュー(Value 新たな価値の発見)、最後にビクトリー(Victory 凱歌の獲得)だ。
これが得られれば文句ない。しかしながら、このうちのいくつかのVを組み合わせて「新たな価値の発見」に結び付けるには、従来のビッグデータ・アナリシスの手法だけでは大きな成果は得られない。何が欠けていたのだろうか。仮説力と物語力を軽視しすぎたと、ぼくは思っている。仮説編集力と物語編集力、まとめていえば仮説的物語編集力が不足しすぎていたのだ。
詳しいことはここでは述べないが(あしからず)、ビッグデータによって幾つもの「V」を得たいのなら、どんな仮説が妥当なのか、どんな仮説をもって前に進むべきなのかということを旗印にするべきなのである。既存のデータの傾向を読み取るだけなら、経験値を超えられない。では、どうするか。対策がないわけではない。
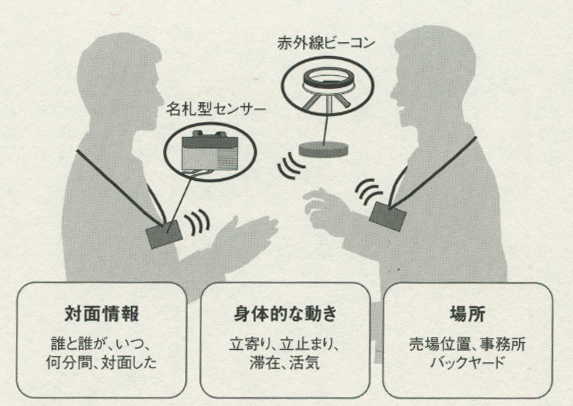
1つは仮説検証型にアプローチすることだろう。これはいくつかの仮説を最初に設定しておいて、これらによる推論が何に到達するかを検証するという方法で、コンサルティングのプロたちが常套手段にしてきた。
が、これだけではやっぱり足りない。この最初に設定するいくつかの仮説には、物語編集の「型」を入れておくべきだったのだ。それによって、与えられた情報を射影(projection)したり適応(accommodation)させたりするときの、表象構造のメカニズムを動かす。いわば「物語の型」を認知的エージェントとして動かして、それによって、何が創発的特徴(emergent feature)になるかを検証してみるべきだったのである。「物語の型」の概要については、『知の編集工学』(朝日文庫)や『物語編集力』(ダイヤモンド社)を読まれたい。
2つめは、仮説探索型によるアプローチを試みることだろう。仮説をあらかじめ設定するのではなく、仮説そのものを探すような組み立てをする。
仮説を探すにはやみくもに探しても徒労におわる。なにしろ相手は蜃気楼のような仮説なのだ。そこで、あらかじめ「仮説の枠組」(仮説らしさのフレーム)についての知識が必要になる。それを仮に「仮説マザー」と呼ぶことにすると、このようなものを組み立てておき、これを機械学習のプロセスに入れる。このとき推論学習が進むにつれ、さまざまな情報の“意味の束”が仮説マザーのどこに絡み付いてくるかを明示するしくみを、工夫しておく。
問題は「仮説マザー」がどういうものかということだが、これについてはビッグデータ業界(もっといえば人工知能業界)ではほとんど見当がついていないはずだ。べつだん出し惜しみをするわけではないが、テキスト構造から仮説性の高いゆらぎを伴う構成特性を集め、これにデノミネーター(分母)を強化させたもの、それが仮説マザーの特徴になる。
しかし考えてみれば、人間が問題を解くにあたって仮説してきたことは、これまでの神話伝説や数学公理や闘争原理の中にほぼすべて含まれているはずなのである。これをちゃんと相手にしてまとめていけばいい。
3つめは編集工学が薦めたい方法で、3Aの思考特質や推論過程を積極的にとりこむというものになる。
3Aは、編集工学的方法論のトリアーデをなしているアナロジー(Analogy)、アブダクション(Abduction)、アフォーダンス(Affordance)のことをいう。いずれも甲乙つけがたい連索的な方法だが、これを別々に扱ってはいけない。組み合わせなければいけない。組み合わせにはニューラルネットワークに学んだアルゴリズムが必要だ。2007年と2011年にダートマス大学ブレインエンジニアリング研究所のリチャード・グレインジャーとアショーク・チャンドラセカールが提案した並列プロセッサのためのアルゴリズムなどが、ヒントになるかもしれない。
ビッグデータ解析や人工知能には、とくにアブダクション(仮説先行的推論プロセス)が必要だ。帰納でも演繹でもなく、その両方を内在化させつつ外在化しうるアブダクションこそは、今後の「知のリバースエンジニアリング」を志向する機械学習や人工知能に肝要なのである。
ついでながら、この3Aによる方法開発には、ぼくはいずれコンティンジェント・システムを想定した情報科学のいっさいが参集されるべきだろうと思っている。コンティンジェンシーとは「別様の可能性」を内包しているシステム様態のことである。コンティンジェンシーを出入りさせることができる両義的(多義的)なシステムがコンティンジェント・システムだ。こう言っただけでは何の見当もつかないかもしれないが(あしからず)、そのごく一端のニュアンスについては、1347夜、1348夜、1349夜、1450夜の千夜千冊、および『インタースコア』(春秋社)に小出ししておいたので、参考にしてほしい。
ともかくもビッグデータ時代の技術と思想は、まだ始まったばかりなのである。どんなふうにするかは、ほぼこれからだ。
インターネットとセンシング・テクノロジーが重なり、高度結合が行き過ぎて「過剰結合状態」になり、世界が「結合思考感染状態」になってしまったのだから、こんな事態になってしまったのはやむをえないことではあるが、けれどもここにこそ、われわれの文明と文化の前途も、コミュニケーション技術の前途も、そして、それに依拠したいと思うビジネスマン諸君のBI(ビジネス・インテリジェンス)の前途も、すべてかかっていると見ておいたほうがいいだろう。
ただし、そういうことを存分に考えたいのなら、データサイエンティストたちと毎日似たような議論をするばかりではなく、いったん「全知と個性」の関係をつなぐために、かつて歴史がどんなことを構想してきたのか、その一部始終のうちの特別な光景を少しゆっくり眺めることも勧めたい。
いったいなぜソクラテスの「問い」から哲学が始まったのか。いったいなぜ春秋戦国期に「諸子百家」が揃ったのか。いったいなぜライプニッツ(994夜)の時代に「ローギッシェ・マシーネ」の構想が生まれたのか。いったいなぜ四則演算とともに「記号」が発明されたのか。いったいなぜ「統計学」とナポレオン戦争と国民国家は同時に登場したのか。いったいなぜチューリング・マシンは「2列の窓のスライド」で成立したのか。いったいなぜ弾道計算とともに生まれたサイバネティクスは「フィードバック」を重視したのか。いったいなぜわれわれはパソコンとインターネットによる「デジタル文化」を受け入れたのか。受け入れたわりにはいっこうにデジタル思考をしない脳と心の正体について、脳科学と認知工学は何を解明しようとしたのか。
これらを少しはゆっくり眺めなおしてみるべきだと思われる。すでにレヴィ=ストロース(317夜)がこんな警告をしていた。「機械の知にトーテムを感じる前に、人類がどんなトーテムに知を託したかを学ぶべきでしょう」。



⊕ 『ビッグデータを開拓せよ』 ⊕
∈ 著者:坂内正夫
∈ 発行者:郡司聡
∈ 発行所:株式会社KADOKAWA
∈ 印刷所:大日本印刷株式会社
∈ 装幀:芦澤泰偉+五十嵐徹
⊂ 2015年9月25日発行
⊗目次情報⊗
∈ 第1部 データが社会を駆動する
∈∈ 序章 ビッグデータの挑戦
∈∈ 第1章 ビッグデータの実像
∈∈ 第2章 データ科学をビジネスに結びつける
∈∈ 第3章 ビッグデータで儲ける3つの原則
∈∈ 第4章 ソーシャルデータを活用する交通システム
∈∈ 第5章 データに語らせる科学
∈∈ 第6章 データの住まうところ
∈ 第2部 技術と社会制度の均衡
∈∈ 第7部 パーソナルデータとビッグデータ
∈∈ 第8部 IDとプライバシーの問題
⊗ 著者略歴 ⊗
坂内正夫(さかうち・まさお)
国立研究開発法人情報通信研究機構理事長、東京大学名誉教授。1946年生まれ。1975年東京大学大学院工学系研究科電子工学専門課程博士課程修了。工学博士。同大学生産技術研究所長、国立情報学研究所長などを経て現職。画像や映像のもつ意味をどのように捉えて処理するかを幅広く研究。一貫してマルチメディア情報処理の先駆的研究に携わってきた。電子情報通信学会ならびに情報処理学会フェロー。2012年フランス共和国レジオン・ドヌール勲章(シュバリエ)受章。2013年情報処理学会功績賞受賞。2015年電子情報通信学会功績賞。