

父の先見



父の先見
ディープラーニングの先にあるもの
KADOKAWA 2015
編集:古川浩司・田中幸宏
装幀:ムシカゴグラフィックス
松尾豊のパワポ・レクチャーをユーチューブで見た。ディープラーニングをめぐる瑞々しい解説だった。1975年生まれの世代だからというのではない。人工知能の濃い薄い、機械学習の得手不得手などについてリアルタイムで経験してきただろうことを、AI史のセミドキュメントをまぜて実況する説明力に長けていて、そこが瑞々しかった。
本書はそのレクチャー内容とほとんど変わらない。だから口語的なところが効いている。きっとライターの田中幸宏がうまくまとめたのだと思う。
ただし、機械学習とディープラーニングの啓蒙を意図したためだろうが、きっと鋭い洞察力を秘めているだろうにそこをあまり突っ込んでいないので、全体としてはややまんべんないものになった。ソフトバンクがフランスのアルデバラン・ロボティクスに頼んで作らせた「ペッパー」のことなど、これっぽっちも褒める必要なんてなかったはずである。
人工知能の揺籃期は、人間の思考や行動の判断を司っている「脳」が、基本的には電気回路に似たニューロンのネットワークの中で「さまざまな計算」をしているはずだという予測に始まっている。
そうだとしたら、「計算」が得意なCPUをもったコンピュータは脳のやっている思考や判断を少しは代行できるのではないか、かなり模倣できるのではないか、脳の知能を外在化するシステムとして取り出せるのではないか。コンピュータ科学者や認知科学者はそう考えた。
このとき原点となったのが、アラン・チューリングの「ユニバーサルマシン」とフォン・ノイマンの自己複製オートマシン「ユニバーサル・コンストラクター」だった。そしてここを出発点にして、人工知能の研究と開発が始まった。
ユニバーサル・コンストラクターの原理は、ぼくが端的にまとめて言ってしまうと、①構築できるものは何でも構築する、②しかし何が構築できるかをあらかじめ教えるようなマシンは作れない、③どんなプログラムも論理的代用でいく、というものだ。
人工知能はこの原理の上にのっている。ただしそこには改良しがたい不文律がある。人工知能が複製できるのは、情報(知識)を与えてもらったものだけだということだ。逆にいえば、その“所与の一件”さえあれば、あとは「計算」に徹すればよい。
では、お手本は何になったのか。それが「脳」(ニューロンの計算モデル)だったのである。
人工知能は脳をお手本にした。しかし脳は「計算」ばかりしているわけではない。多様なニューロトランスミッター(脳内物質)をシナプスで放出したり制御したりして、さまざまな化学的プロセスを“解釈”しているだろうし、かつてロジャー・ペンローズ(4夜)が仮説したように微細な量子現象によって「意味」を“解読”しているのかもしれない。
ペンローズは麻酔医学のスチュワート・ハメロフと組んで、脳のマイクロチューブル(MT)がニューロンたちの接続を助け、学習や理解の推進にかかわっていると見た。マイクロチューブルを構成するタンパク質が変性するからだという仮説である。
最近はジュリオ・トノーニの『意識の統合情報理論』に出てくる「Φ」(ファイ)が注目されて、脳の情報活動の活性度のようなものを確率的に計算できるのではないかとも言われている。トノーニの仮説についてはそのうち千夜千冊するつもりだ。
しかし、こういうことはいまのところ確証できていない。ぼくの父は胆道癌と膵臓癌を併発したとき年齢退行をおこし、最期は3~4歳の言葉づかいで幼児記憶を放出していたが、こんな「脳の奥の出来事」がどのようにおこっているのかは、ほとんど見当がついていないのだ。
が、それはそれとして、脳とコンピュータに共通する「計算」のプロセスやパターンに注目することは、脳科学にとってもコンピュータ科学にとってもなんらかの共通有効性をもつだろうことは、それでも成立する。そしてそこに自動的自己学習をする人工知能という「ありかた」が生まれてくることも、ありうる。コンピュータがそういうことを成立させるだけのべらぼうな器量をもってきたからだ。
こうして人工知能という研究と開発にも、いろいろな“器量よし”が出てくるようになった。
その本質を一言で言いあらわすのは難しいが、スチュワート・ラッセルらの有名な教科書『エージェント アプローチ 人工知能』(共立出版)の言い方を借りれば、ずばり「入力によって出力が変わるエージェント」が人工知能なのである。松尾はこの見方にもとづいて、今日の人工知能のレベルを4段階にまとめた。わかりやすいものになっている。
レベル1「単純な制御プログラム」
エアコン、掃除機、電動シェーバーなどの制御工学あるいは
システム工学が装填されているもの。情報家電製品には「人
工知能搭載」と謳っているものが多いが、これらは実際には
人工知能とは言えない。
レベル2「古典的な人工知能」
将棋やチェスのプログラム、お掃除ロボット、パズル対応ソ
フト、質問対応ソフト、診断プログラムなど。ふるまいのパ
ターンが多彩なものに対応した人工知能。知識ベースが入っ
ていることも多い。
レベル3「機械学習ができる人工知識」
検索エンジンに内蔵されたり、ビッグデータをもとに自動的
な判断をするような人工知能。機械学習のアルゴリズムが使
われる。機械学習とはサンプルとなるデータ群をもとにルー
ルと知識を自分で学習できることをさす。
レベル4「ディープラーニングを採り入れた人工知識」
機械学習をするときのデータをあらわす変数(特徴量)自体
を自己学習する人工知能。いわゆるディープラーニングでき
る人工知能。松尾はディープラーニングのことを「特徴表現
学習」とも名付けている。
本書が言及する人工知能は主としてレベル3とレベル4の機械学習レベルのことである。
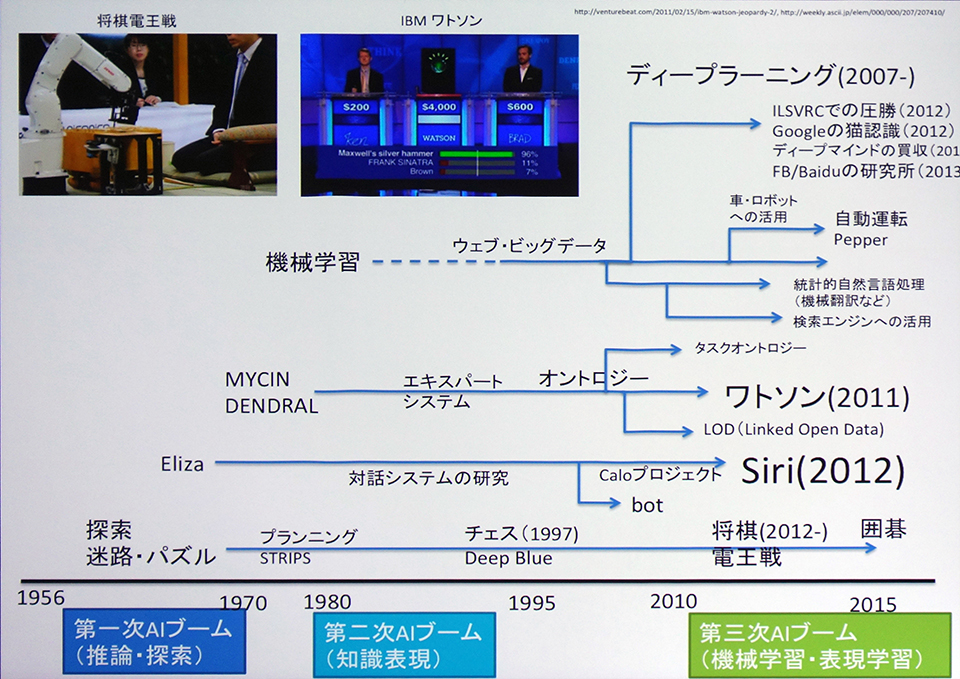

長らく地味だった機械学習がしだいに注目されるようになったのは、パターン認識技術(文字認識・画像認識)の成果が著しく上がってきたことと、ウェブなどに情報や知識が大量にたまってきたためだった。
言い換えればセンシングデータとビッグデータがたまったからだ(1601夜)。インターネットの想像を絶する拡充とともに、機械学習のしくみと説得力が浮上したのである。
浮上するにあたって強力な主要武器になったのは、「統計的自然言語処理」(Statistical Natural Lauguage Proccesing)である。これは、「ともかく確率の高いほうから情報処理していこうぜ」という腹をくくった方法の権化のようなもので、たとえば機械翻訳なら文法構造や意味構造をほったらかしにして、訳される確率の高いほうから機械が対処していくという方式だ。日英・英日の機械翻訳なら日本語と英語の両方が記載されている対訳コーパスを大量に用意しておいて、このテキストのデータを次々にあてはめていくというやりかたをとる。
こんなことで「構文」や「意味」にちゃんと到達できるのかと、個性的な才能を重視する諸君からするとなんとも訝しく思うだろうが、これを人工知能のプログラム自身が自己学習していくことによって、かなりの正答率を実現できることがわかってきた。機械学習さまさまなのだ。
さまさまなのだが、もちろん“人の手”による独自の工夫は必要で、この工夫になかなか気が付かなかったところが、これまで長らく人工知能が「冬の時代」の辛酸を嘗めてきた理由だった。
工夫は幾つかあるが、基本的には「分ける」の工夫をした。
もともと学習というものは「分ける」から始まり、「分ける」が「変わる」を呼んで「分かる」をおこすというふうになっていく。イシス編集学校ではこれを「かわると、わかる」「わかると、かわる」と言っている。「わかる」と「かわる」をつないでいるのが「わける」なのである。
分けてどうなるかといえば、その分けたもの(モノでも情報でも)を「取ってこられる」。こうした学習プロセスの綿密な観察から、「分節化」(アーティキュレーション)をどうするかという科学や工学が生まれてきた。
分けるためには、基本的には情報群(データ群)が次々にうまく分かれるような線を引けばいい。線引きをどうするかということだ。ただ、これまでの人工知能は、その「うまく分かれるように引く」ということばかりにとらわれていた。
そこでいろいろ工夫した。たとえば、一番近くの隣りの情報との関係をチェックするという「最近傍法」(Nearest Neighbor)や、ベイズの定理を使って、データの特徴ごとにどのカテゴリーをあてはめるのかを算定してそれらを足していくというナイーブベイズ法(Naive Bayes)などだ。
けっこう前から認知科学ギョーカイで流行していたやりかたも、あらためて見直された。「バックプロパゲーション」(Back propagation)をかけるという方法だ。分けた全体の誤差(間違う確率)が少なくなるように微分をとるのである。誤差を逆伝播によって調整するのでバックプロパゲーションというのだが、データに対する重み付けをひとつずつ点検していくということでは、手間もかかる。
工夫の効果が上がったのは、1601夜にも紹介したサポートベクターマシン(SVM)だった。これは二つの情報(データ)を分けるときに、その二つの情報がもつ識別度が互いに遠くなるようなところで線を引くというやりかたで、数理的にはマージン(余白・余裕度)を最大にとるというふうにする。マージン最大基準の導入によって識別誤り度を低くする。まあ、いろいろの工夫があったわけだ。
そもそも言葉や概念というものは、その発生時からして厄介なものなのである。厄介だからおもしろく、だから詩歌も小説も会話も商品名の競争も絶えないのだが、これをいざ機械が処理しようとすると、一筋縄ではいかない。どんな言葉も概念も、すっきりした所属をあらわしてはいないからだ。
「木」という言葉は日本語や英語やドイツ語やスワヒリ語では異なる表現をするし、その所属も「植物」「森」「林」「土」にも、「鉄」や「紙」との対比にも五行思想にも関係する。木工・材木・雑木林・擬木・木曜日といった熟語には、なお困る。これが「木」のような概念ではなく、「美徳」「国家」「空気」「たのしみ」「嫌になる」「結構」などとなると、もっと面倒だ。西洋哲学ではこの面倒をぶった切るために「オッカムの剃刀」の必要が議論されてきた。
人工知能が概念を扱うにあたっても、以前から「フレーム問題」や「シンボル・グラウンディング問題」が取り沙汰されてきたのはそのせいだ。この二つは、人工知能システムや人工知能を搭載したロボットが「分ける」「取ってくる」というタスクをどのように処理するかというときの難問だった。
人間は「あのコップを取ってきてくれ」というお題には、誰だってたやすく判断行動をおこす。幼児もよろこんでこのタスクに挑戦し、よちよち歩いてお母さんに両手に挟んだコップを渡す。
ところがコンピュータやロボットでは、「あのコップ」がテーブルや棚やお盆に所属するのかどうかから判断しなければならない。コンピュータやロボットが持っている知識マップに、コップの帰属や所属が一義的に記述されていればそれでいいというものではない。
「コップはときにお盆にのっている」という知識マップがあれば、AIロボットはそのお盆と分けられるコップだけを持ってくることをするが、仮に「コップは棚にある」という記述だけがあって、「コップは棚板でできている棚の上にある可能性が高い」という記述がないと、ロボットは棚板ごと引きちぎってコップを持ってきてしまう。
つまり言語や概念がどんな知識のフレームをもっているのか、そのことを機械が峻別しようとするとかなり難しい処理が必要になるわけだ。これを「フレーム問題」と言ってきた。
ちなみにイシス編集学校では、比較的早い時期に「コップの言い換え」というエクササイズをする。コップに内属している要素・機能・属性を確認しつつも、コップに内包されうる意味をあらかじめふくらませておくためだ。編集学校は世間の分節常識にとらわれないで、自由なフレームや分節に遊ぶことを奨励する学校なので、そこは人工知能がめざすところとはいささか異なっているのである。
もっとも近い将来は「編集工学的人工知能」も大いにありうることで、その場合は入力と出力との「あいだ」が見えるようなもの、その「あいだ」からタスクやイメージが発見できるものになるだろう。
「シンボル・グラウンディング問題」はまた別の問題である。たとえばシマウマはあきらかに「シマ」と「ウマ」という言葉からできている合成語だが、機械がそれだけを頼りにシマウマをあらわすと、「島にいる馬」や「縛られた馬」になりかねない。実際の生きたシマウマには形態も生態もあるけれど、機械はそんなイメージをもってはいないのだ。 だからシマとウマの知識があるからといって「シマウマ」がわかるとはかぎらない。そこにはシマウマという蓋然的なシンボル・イメージについてのなんらかの理解が必要なのである。
が、この蓋然性をコンピュータに納得させるのが、なかなか難しい。すでにコンピュータはシマやウマの一義的な基本記述を持ってしまっているうえに、コンピュータはシステムの中に「自然」も「現実」もまったく持っていないので、実世界との接地(グラウンディング)がおこりにくいのだ。
人間の知性や知能は、現実の対象の全貌を知ったうえでシンボルを理解しているのではない。いつのまにか「リンゴ」や「極楽」や「時間がたつ」というシンボル操作ができるようになっている。人間は心象の内部で対象を動かしているからだ。心的に想起されているからこそ、シンボルが動くのである。
しかしコンピュータやゲームプログラミングやロボットでは、このシンボル操作がなかなかできない。そこで仮想空間をつくって、エージェントの内部にシンボルについての知識操作ができるようにする。それには地形であればナビゲーション・データを埋め込み、オブジェクトであればパラメータを添付したスマートオブジェクトをつくらなければならない。
とはいえだからといって、コンピュータが実世界に接地できたわけではない。これをさらに有効にするにはどうすればいいのかというのが「シンボル・グラウンディング問題」なのである。スティーブン・ハルナットが提起した難問だった。
シンボル・グラウンディングはエルンスト・カッシーラーやスザンヌ・ランガーの『シンボルの哲学』『シンボル形式の哲学』このかた、ぼくがずっと気にしてきた問題でもあった。シンボルは象徴や表象のことだけれど、たいへん人間くさい「思い浮かべ」なので、なかなか論理的な説明や数理的な落とし込みがやりにくいのだ。
だいたいシンボルは夢の中にも出てくるし、想像の中にも頻繁に出入りする。古代中世の神話や説話や昔話は怪物やら不思議な光りものやら妖精やら、シンボルだらけである。「となりのトトロ」「バットマン」「モノリス」もみんなシンボルだ。
そのためシンボルについては、エリアーデ(1002夜)は神の発生にまで立ち戻らないとわからないものとして、カール・ユング(830夜)は集合的無意識のようなものをともなうものとして、フロイト(895夜)はコンプレックスの中に畳み込まれたものとして、ホワイトヘッド(995夜)は認識作用のプロセスまるごとの中に作用しているものとして、チャールズ・サンダース・パース(1182夜)は記号そのものの本質が受けもつものとして、それぞれ議論した。
ジャック・ラカン(911夜)の精神分析学のように、シンボルは「自己」の内部の鏡像過程に生じているとみなしている見方もある。
こんなふうに、定義しようとしたり、どこかに位置付けしようとすればするほど、掴みどころがなくなってくるシンボルなのだが、ふだんのわれわれはシンボルにもアイコンにも、アレゴリーにもメタファーにもちっとも困らない。とくにアーティストたちは大胆自在にシンボルばかりをあらわしてきた。
シンボルの正体はまだわかっていないのだ。こんなわけなので、そういうシンボルを意識的に扱うには、いったんシンボルが湧いてくるプロセスのことと、それが投影される場面とを分けて考えなければならないだろうと、ぼくはずっと思ってきた。
そこで編集工学では、シンボルや象徴的な意味論を扱うにあたっては、それが発祥する分母像(地=グラウンド)とそこから派生する分子像(図=フィギュア)とを適宜入れ替えながら進む動的なプログラムをテストすることを推奨してきたのである。

言葉、知識、情報、データ、メッセージというものは、最小分割されたひとつずつのアトミックアイテムを限定して記述できないようになっている。人間は古代このかた、また幼いときから、そうやって育ってきたからそれでいいのだが、人工知能では、限定すればするほど関連リンクをふやしておかなければならないということになる。
これは大変だ。第五世代コンピュータはこのリンクの厖大さに付き合っているうちに挫折した。挫折したのは、ひとつずつをアトミックな記述として扱いすぎたことにあった。それならたとえば「ひとつに二つ」というふうにしてみたらどうか。
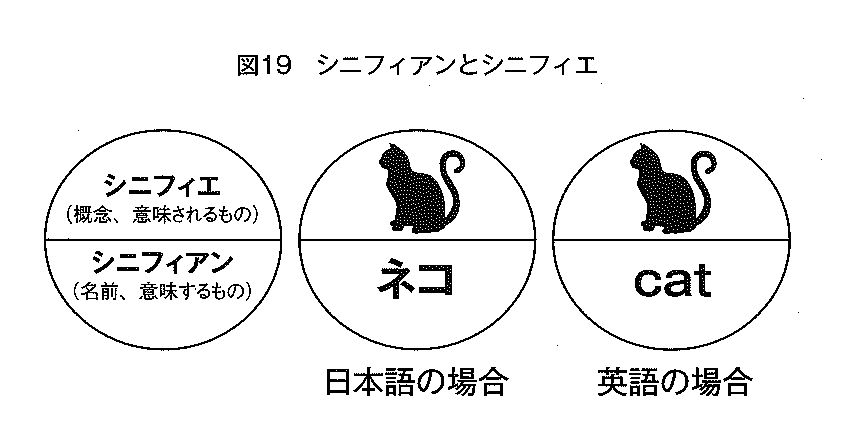
スイスの言語哲学者フェルディナン・ド・ソシュールは言語は記号的に成り立っていると見て、言語を「記号のシステム」と見立て、その言語記号を「シニフィエ」(概念)と「シニフィアン」(名前)に分けた。シニフィエが「記号の内容=意味されるもの」で、シニフィアンが「記号の表現=意味するもの」だとみなした。たいへん単純な組み立てだが、それでもここには「ひとつに二つ」のセットで一つの言語記号を扱えるというしくみができあがった。これなら機械のほうはちょっと楽になる。
こうした「分け方」の工夫をあれこれ試して、問題に対して効率的に対処するということを、人工知能では総称して「フィーチャー・エンジニアリング」(feature engineering)と言っている。特徴量をどう設計しておけばいいのかという問題だ。特徴量は機械学習において入力に使うパラメーターのことをいう。このパラメーターをどのようにしておくか(どの変数を選ぶか)ということが、人工知能の予測精度を激変させるのである。
というようなことをあれこれ説明しながら、松尾はこれらの問題を巧みに前提にしつつ、ディープラーニングこそが「特徴表現学習」を容易にさせるというふうに、人工知能の明日を指針していった。「特徴表現学習」は松尾の発案によるものだ。
ところで、本書でなるほどと膝を打ったところが、いくつかあった。ぼくが知らないだけでギョーカイでは有名なのかもしれないが、いずれもディープラーニングの手法や工夫に関することとして編集工学的にも興味をもった。二つあげておく。
ひとつは、特徴表現学習のために「概念」を扱うときに、あえて入力信号にノイズを加えておくという手法だ。そうしておくと、ノイズを加えても加えても出てくる「概念」のロバスト性が上がるという。言い換えれば「ちょっと違ったかもしれない過去」を含ませておいたほうが、有意的な取り出し率がよくなり、その「概念」がシステムの中で頑健に動くというのだ。なるほど、なるほどだ。
もうひとつは、やはり有効に「概念」を動かそうとするとき、それがニューラルネットワーク上のプロセッシングであったとすると、そのネットワークのニューロンの一部をあえて欠落させておくという手法だ。そうすると当然、データがあるべきところに当てになるデータがないのだから、別に「あてど」(当て度)を補填するところを探したり学習することになる。
たとえば都道府県の天候予想のソフトをつくるとき、東北地方の天候を予測するのに「東北」の項目を落しておく。システムはやむなく「北日本」「陸奥」「太平洋側」「日本海側」「仙台空港」「東北新幹線」などの項目で補填をすることになるのだが、これが案外大事な力をつけるのである。ある特徴量が他の特徴量をカバーするように最適化されていくからだ。逆にいえば、ある特徴量に過度に依存したワイヤーが削げ落ちる。
これもなるほどである。というよりも、ぼくはかねて『知の編集術』(講談社現代新書)の冒頭で「編集は照合である」「編集は連想である」、そして「編集は不足から始まる」と書いておいたのだが、まさにこの「不足による補強」が機械学習(ディープラーニング)にも応用されていることにほっとした。

あらためて言うまでもないだろうが、人工知能は「考えている」わけではない。iPhoneに会話をすると何か答えてくれるような気がするが、これは音声認識プログラム「Siri」が辞書を高速に引きながら曖昧な応接しているだけで、会話の内容を「理解」しているわけではない。まして考えてもいない。
しかし、いったい「考える」とは何かというと、実はぼうっとアタマの中だけで考えるなんてことは、われわれもしていない。われわれのアタマは“ゼロのデフォルト状態”などもちえない。いつだって何かがうごめいている。
まず言葉を使う。その言葉はアタマの中を行ったり来たり、ふらふらしていて、うまく管理されているわけではない。言葉は操作記号と同じトークンにすぎず、その言葉も本人が作ったのではなく「使って」いるだけである。日本語も英語も歴史の総体がつくりあげたものだった。
そういう言葉が文章のようにつながったり、メッセージになったり、文脈をもつわけだが、これもわれわれが「考えた」から発信できているとは言い切れない。結婚式の祝辞に下書きのメモが必要だったりするように、どこかに「仮想テキスト」が想定されているのである。ダニエル・デネット(969夜)は、脳では「多元的草稿モデル」が編集されている、と言った。
われわれは、何かツールがなければ、ちゃんとは考えられないのだ。そのツールもしょっちゅう使っているのではない。使っていないときは、たいてい大小の「連想」をしている。連想はアソシエーションということだが、つまりはいろいろな言葉を組み合わせているのだ。まことにおぼつかない。
しかし、いざこのうちの何かを話したり書いたりして出力しようとすると、とたんに最適化(optimaization)や精緻化(elaboration)を試みる。これが表現(representation)になる。こうなると、この一連のプロセスは人工知能がやろうとしていることと、そんなに変わりない。
われわれの知能の使い方と人工知能のプロセスは、まったく別のものなのではないのだ。とはいえ、本来の知能とは何かということは、人工知能から逆算してわかることではない。なぜなのか。そこには「意識」という怪物が介在するからだ。いまのところ、人工知能を突きつめても見えてこないもの、それが「意識」というものである。
本書のタイトルは『人工知能は人間を超えるか』だが、人間を超えるのではなく、「人間っぽくなる」のをめざしたいのだとしても、それは「意識のモデル化」に挑んでからのことなのだ。
今夜の話はこのくらいにしておく。しばらくこの続きを千夜千冊するので、よかったらついてきてほしい。

⊕ 『人工知能は人間を超えるか―ディープラーニングの先にあるもの』 ⊕
∈ 著者:松尾豊
∈ 発行者:川金正法
∈ 発行所:株式会社KADOKAWA
∈ 印刷所:暁印刷
∈ 装幀:ムシカゴグラフィクス
∈ 製本:BBC
⊂ 2015年3月10日 第一刷発行
⊗目次情報⊗
∈∈ 広がる人工知能
――人工知能は人類を滅ぼすか
∈ 第1章 人工知能とは何か
――専門家と世間の認識のズレ
∈ 第2章 「推論」と「探索」の時代
――第1次AIブーム
∈ 第3章 「知識」を入れると賢くなる
第2次AIブーム
∈ 第4章 「機械学習」の静かな広がり
――第3次AIブーム(1)
∈ 第5章 静寂を破る「ディープラーニング」
――第3次AIブーム(2)
∈ 第6章 人工知能は人間を超えるか
――ディープラーニングの先にあるもの
∈∈ 終 章 変わりゆく世界
――産業・社会への影響と戦略
⊗ 著者略歴 ⊗
松尾 豊
東京大学大学院工学系研究科 准教授。1997年、東京大学工学部電子情報工学科卒業。2002年、同大学院博士課程修了。博士(工学)。同年より産業技術総合研究所研究員。2005年よりスタンフォード大学客員研究員。2007年より現職。専門分野は、人工知能、ウェブマイニング、ビッグデータ分析。人工知能学会からは論文賞、創立20周年記念事業賞、現場イノベーション賞、功労賞の各賞を受賞。2012年から人工知能学会 編集委員長・理事。日本トップクラスの人工知能研究者の一人。著書に『人工知能は人間を超えるか ディープラーニングの先にあるもの』(KADOKAWA / 2015)、共著書に『東大准教授に教わる「人工知能って、そんなことまでできるんですか?」』(KADOKAWA / 2014)。